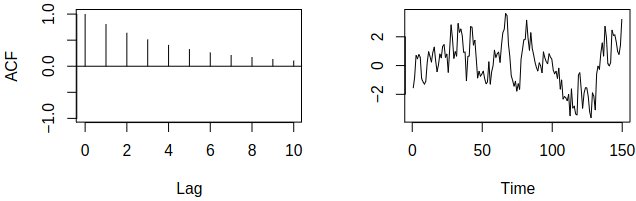
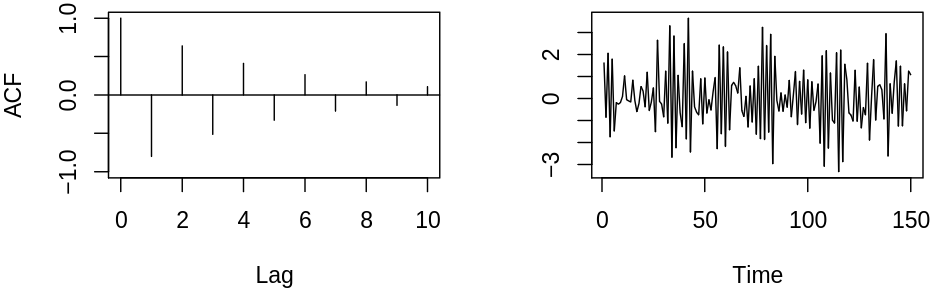
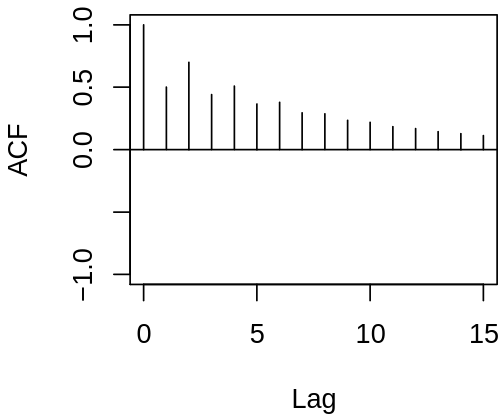
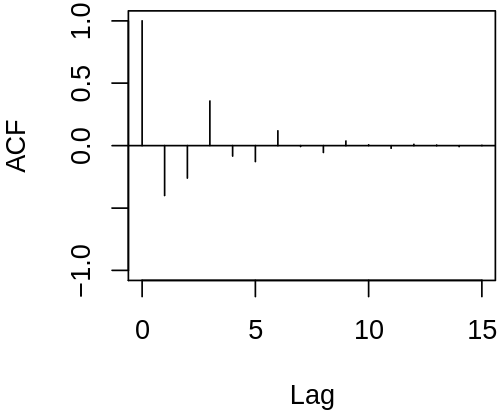
Our motivation for the last lecture was to describe autocorrelated time series. Thus we should study the autocorrelation structure of ARMA models. Consider now an \(\MAmod{q}\) process \[
\rX_t = \rve_t + \tht_1 \rve_{t-1} + \dots + \tht_q \rve_{t - q},
\] where \(\set{\rve_t} \sim \WN{0}{\sigma^2}\). Recall that \(\acov(h) = \acov(-h)\) and compute for \(h \geq 0\)\[
\begin{aligned}
\acov(h) &= \cov (\rX_t, \rX_t+h) \\
&= \cov \brackets{\sum_{j = 0}^q \tht_j \rve_{t-j}, \sum_{j = 0}^q \tht_j \rve_{t+h-j}} \\
&= \begin{cases}
\sigma^2 \sum_{j = 0}^{q-h} \tht_j \tht_{j+h}, & 0 \leq h \leq q, \\
0, & h > q
\end{cases}
\end{aligned}
\] and that the autocorrelation function \(\acf\) has, in this case, the form \[
\acf(h) = \begin{cases}
\frac {\sum_{j = 0}^{q-h} \tht_j \tht_{j+h}} {\sum_{j = 0}^q \tht_j^2}, & 0 \leq h \leq q, \\
0, & h > q.
\end{cases}
\]
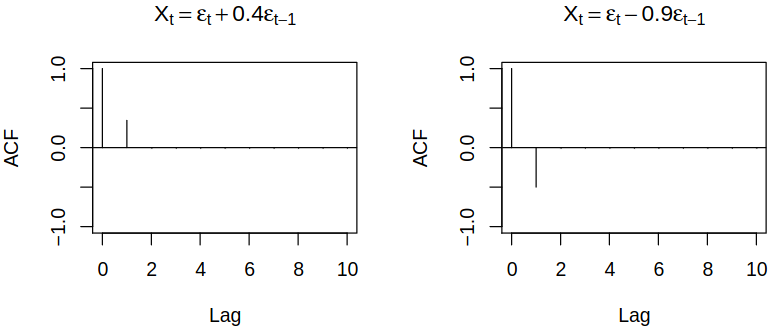
To illustrate the preceding derivations, consider the following \(\MAmod{1}\) processes and observe \[
\acf(1) = \frac {\tht_1}{1 + \tht_1^2}, \quad \acf(h) = 0
\] for \(h >1\).
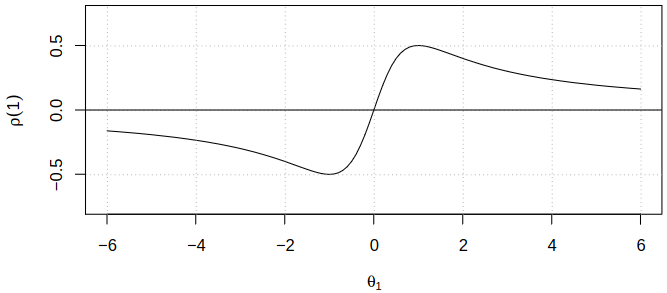
Dependence of \(\acf(1)\) on \(\tht_1\)
Notice that \(\absval{\acf(1)} \leq 0.5\) and it has maximum at \(\tht_1 = \pm 1\). Also, observe that for most values of \(\acf(1)\) there exist 2 choices for \(\tht_1\). From the fact that \(\absval{\acf(1)} \leq 0.5\) follows that we cannot use \(\MAmod{1}\) to model data with acf \((1, 0.7, 0, 0, \dots)\). Consider now \(\MAmod{2}\) models and look at their autocorrelations.
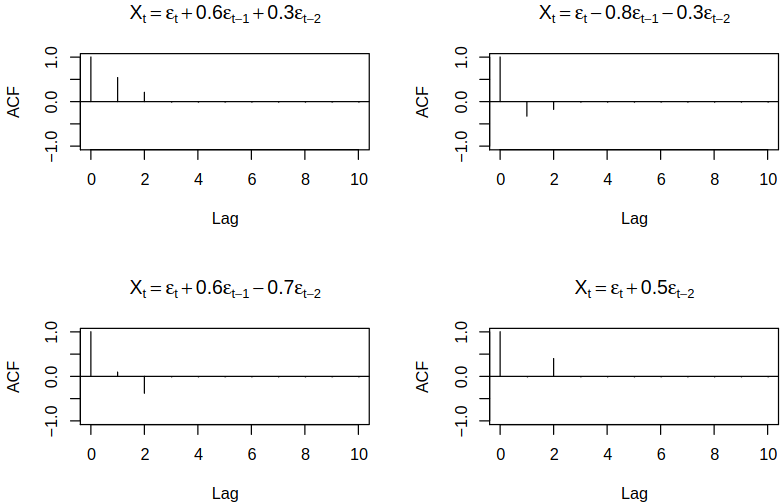
Autocorrelations of \(\MAmod{2}\) models
It can be computed that \[
\acf(1) = \frac{\tht_1 + \tht_1 \tht_2} {1 + \tht_1^2 + \tht_2^2}, \quad \acf(2) = \frac {\tht_2} {1 + \tht_1^2 + \tht_2^2}, \quad \acf(h) = 0
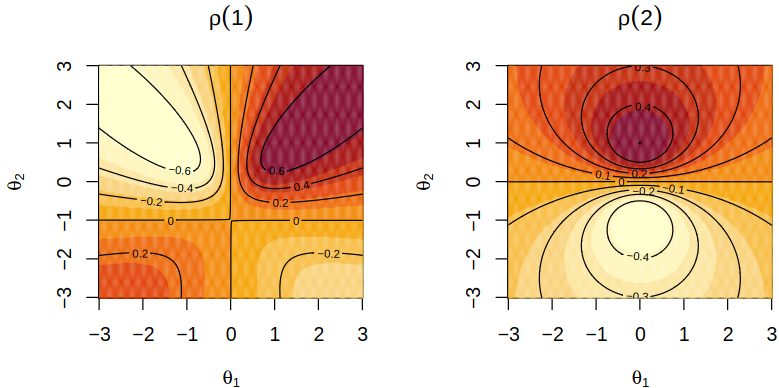
\] for \(h > 1\), which can be seen in Figure 8.1. It can also be shown easily that \(\absval{\acf(2)} \leq 0.5\) with maximum at \(\tht_1 = 0\) and \(\tht_2 = \pm 1\).
Figure 8.1: Depedence of \(\acf\) on \(\tht_1, \tht_2\)
8.1 Autocorrelation of the AR process
Let \(\rX_t\) be a causal\(\ARmod{p}\) process \[
\rX_t = \vf_1 \rX_{t-1} + \dots + \vf_p \rX_{t-p} + \rve_t,
\] where \(\set{\rve_t} \sim \WN{0}{\sigma^2}\). Since \(\set{\rX_t}\) is causal, we see that \(\rX_t = \sum_{j = 0}^\infty \psi_j \rve_{t-j}\) and thus \(\expect \rX_t = 0\). Now compute for \(h \geq 0\) that \[
\begin{aligned}
\acov(h) &= \Expect{\rX_t \rX_{t-h}} \\
&= \Expect{\brackets{\vf_1 \rX_{t-1} + \dots + \vf_p \rX_{t-p} + \ve_t} \rX_{t-h}} \\
&= \vf_1 \acov(h-1) + \dots + \vf_p \acov(h - p) + \sigma^2 \indicator{h = 0}.
\end{aligned}
\] For \(h \geq p\) we get \[
\acov(h) - \vf_1 \acov(h - 1) - \dots - \vf_p \acov(h - p) = 0
\] or by dividing through by \(\acov(0)\) it yields \[
\acf(h) - \vf_1 \acf(h - 1) - \dots - \vf_p \acf(h - p) = 0,
\] which are called the Yule-Walker equations.
Caution
Here we can see that we started with some difference equation, then we added a stochastic part, but on the autocorrelation level, we still have the same difference equation. For polynomial decay time series, we have to use different methods/models.
Thus we recognize that \(\acov(h)\) (or \(\acf(h)\)), \(h = 0,1,\dots\), satisfies the (deterministic) \(p\)-th order difference equation (for \(h \geq p\)) \[
\acf(h) - \vf_1 \acf(h - 1) - \dots - \vf_p \acf(h - p) = 0,
\] i.e. \(\arPoly(\backs) \rho(h) = 0\). The general solution then is \[
\acf(h) = \sum_{j = 1}^r \sum_{k = 0}^{m_j - 1} c_{jk} h^k \xi_j^{-h}
\] where \(\xi_j\) are the distinct roots of \(\arPoly\) with multiplicities \(m_j\), \(\sum_{j = 1}^r m_j = p\). The initial conditions then become \[
\acf(0) = 1, \quad \acf(h) - \vf_1 \acf(h - 1) - \dots - \vf_p \acf(h - p) = 0,
\] where \(h = 0,1,\dots, p-1\). To compute \(\acov(0)\) (and thus \(\acov(h)\)), divide the equation for \(\acov(h)\) at \(h = 0\) by \(\acov(0)\) and solve to get \[
\acov(0) = \sigma^2 / \brackets{1 - \vf_1 \acf(1) - \dots - \vf_p \acf(p)}.
\]
Tip
For AR processes, expect very fast (exponential) decay in parameter values – this can also be seen in their autocorrelations.
Example 8.1 Together, the autocorrelation of \(\ARmod{1}\) process \[
\rX_t - \vf_1 \rX_{t - 1} = \rve_t
\] has the following corresponding difference equation \[
\acf(h) - \vf_1 \acf(h-1) = 0, \quad h \geq 1,
\] which is solved by \[
\acf(h) = \vf_1 \acf(h - 1), \quad h \geq 1.
\] Given the initial condition \(\acf(0) = 1\), this transforms to \[
\acf(h) = \vf_1^h, \quad h \geq 0
\] and then \(\acov(0) = \sigma^2 / (1 - \vf_1^2)\).
Note
This can also be solved using the causal representation.
Consider a causal\(\ARMA p q\) process \[
\rX_t = \vf_1 \rX_{t-1} + \dots + \vf_p \rX_{t-p} + \rve_t + \tht_1 \rve_{t-1} + \dots + \tht_q \rve_{t-q},
\] for which surely \(\expect \rX_t = 0\), which follows from the causal representation \(\rX_t = \sum_{j = 0}^\infty \psi_j \rve_{t-j}\). We can then compute for \(h \geq 0\) that \[\begin{align*}
\acov(h) &= \Expect{\rX_t \rX_{t-h}} = \Expect{\brackets{ \sum_{j = 1}^p \vf_j \rX_{t-j} + \sum_{j = 0}^q \tht_j \rve_{t-j} } \rX_{t-h}} \\
&= \sum_{j = 1}^p \vf_j \acov(h-j) + \sigma^2 \sum_{j = 0}^q \tht_j \psi_{j-h},
\end{align*}\] because \[
\Expect{\rve_{t-j} \rX_{t-h}} = \Expect{\rve_{t-j} \sum_{k = 0}^\infty \psi_k \rve_{t-h-k}} = \sigma^2 \psi_{j-h}.
\] For \(h \geq \max \set{p, q+1}\), we get homogeneous difference equations \[
\acov(h) - \vf_1\acov(h-1) - \dots - \vf_p \acov(h-p) = 0
\] or \[
\acf(h) - \vf_1\acf(h-1) - \dots - \vf_p \acf(h-p) = 0.
\] Given the initial conditions \[
\acov(h) - \vf_1\acov(h-1) - \dots - \vf_p \acov(h-p) = \sigma^2 \sum_{j = h}^q \tht_j \psi_{j-h}
\] for \(h = 0, \dots, \max \set{p, q+1} -1\). The general solution with the initial conditions stays the same as in the homogeneous case. Lastly, from the fact that \(\rX_t\) is causal, we get that \(\absval{\xi_j} > 1\) and thus \(\acf(h)\) converges exponentially fast to zero as \(h \to \infty\) (in sinusoidal fashion if some of the roots are complex).
8.2 Partial autocorrelation
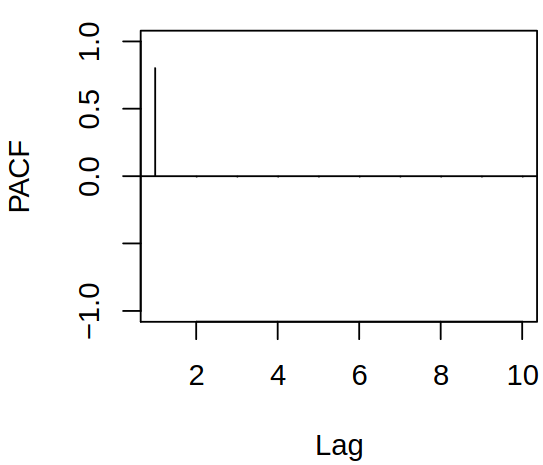
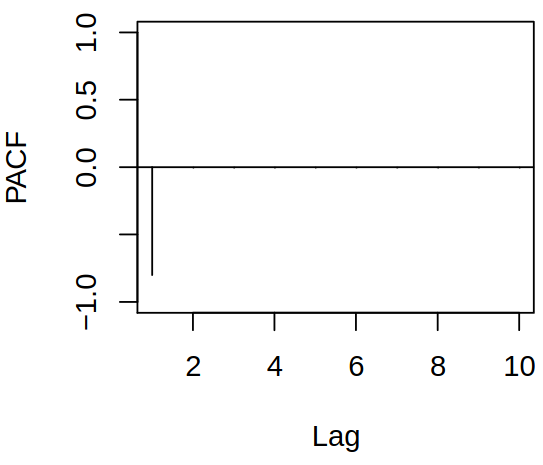
We have seen that for an \(\MAmod{q}\) process \(\acf(h) = 0\) for \(h > q\) and \(\acf(q) \neq 0\), thus \(\acf\) provides information about \(q\). On the other hand, for \(\ARmod p\), no such cut-off exists, as \(\acf(h)\) exponentially dampens. Therefore we might look for an analog of the autocorrelation that would provide information about the order of autoregression.
Consider now \(\ARmod{1}, \rX_t = \vf_1 \rX_{t-1} + \rve_t\). Then \(\corr (\rX_t, \rX_{t-2}) \neq 0\), because \(\rX_t\) is dependent on \(\rX_{t−2}\) through \(\rX_{t−1}\) and the dependencies are linear. Thus we need to break the dependence chain and remove the linear effect of everything in-between.
Definition 8.1 (Partial correlation) The partial correlation between mean zero variables \(\rnd Y_1\) and \(\rnd Y_2\) given \(\vr Z = (\rnd Z_1, \dots , \rnd Z_m)\Tr\) is defined as \[
\parcorr{\rnd Y_1}{\rnd Y_2}{\vr Z} = \corr (\rnd Y_1 - \estim{\rnd Y}_1,\rnd Y_2 - \estim{\rnd Y}_2),
\] where \(\estim{\rnd Y}_j\) is the best linear prediction (BLP) of \(\rnd Y_j\) from \(\vr Z\).
Here the BLP takes the form \(\estim{\rnd Y}_j = \estim \beta_1^{(j)} \rnd Z_1 + \dots + \estim \beta_m^{(j)}\rnd Z_m\) where \((\estim \beta_1^{(j)}, \dots, \estim \beta_m^{(j)})\) is the minimizer of \(\Expect{\rnd Y_j - \estim \beta_1^{(j)} \rnd Z_1 - \dots - \estim \beta_m^{(j)}\rnd Z_m}\). Thus \(\parcorr{\rnd Y_1}{\rnd Y_2}{\vr Z}\) is the correlation between \(\rnd Y_1\) and \(\rnd Y_2\) when the linear effect of \(\vr Z\) is removed. Clearly, for a multivariate Gaussian distribution, the BLP equals the conditional expectation and hence \(\parcorr{\rnd Y_1}{\rnd Y_2}{\vr Z} = \corr (\rnd Y_1, \rnd Y_2 \condp \vr Z)\).
Note
This concept relates to the precision (concentration) matrix \[
\vi P = \variance (\rnd Y_1, \rnd Y_2, \vr Z)\Inv: \quad \parcorr{\rnd Y_1}{\rnd Y_2}{\vr Z} = - P_{12} / \sqrt{P_{11} P_{22}}.
\]
Definition 8.2 The partial autocorrelation function (PACF) of a stationary process, \(\set{\rnd X_t}\), denoted as \(\pacf(h)\), is defined for \(h = 1, 2, \dots\) as \[
\pacf(1) = \corr(\rX_t, \rX_{t+1}) = \acf(1)
\] and \[
\begin{aligned}
\pacf(h) &= \corr(\rX_t - \estim{\rX}_t, \rX_{t+h} - \estim{\rX}_{t+h}) \\
&= \parcorr{\rX_t}{\rX_{t+h}}{(\rX_{t+1}, \dots, \rX_{t+h-1})\Tr}, \quad h = 2,3,\dots
\end{aligned}
\] where \(\estim{\rX}_t\) and \(\estim{\rX}_{t+h}\) are the best linear predictions of \(\rX_t\) and \(\rX_{t+h}\) from \(\rX_{t+1}, \dots, \rX_{t+h-1}\).
Let now \(\rX_t\) be a causal \(\ARmod{p}\) process, \(\rX_t = \vf_1 \rX_{t-1} + \dots + \vf_p \rX_{t-p} + \rve_t\). For \(h > p\), compute the mean squared prediction error for prediction of \(\rX_{t+h}\) from \(\rX_{t+1}, \dots, \rX_{t+h-1}\), which we want to minimize, \[
\begin{aligned}
&\Expect{\rX_{t+h} - \beta_1 \rX_{t +h - 1} - \dots - \beta_{h-1} \rX_{t+1}}^2 \\
&= \Expect{\ve_{t+h} + \sum_{j = 1}^p (\vf_j - \beta_j) \rX_{t+h-j} - \sum_{j = p+1}^{h-1} \beta_j \rX_{t+h-j}}^2 \\
&= \expect \rve_{t+h}^2 + \Expect{\sum_{j = 1}^p (\vf_j - \beta_j) \rX_{t+h-j} - \sum_{j = p+1}^{h-1} \beta_j \rX_{t+h-j}}^2 \geq \expect \rve_{t+h}^2
\end{aligned}
\] with the assumption that there is no correlation between \(\rve_{t+h}\) and the past. The minimum is attained at \(\beta_j = \vf_j\) for \(j = 1, \dots, p\) and \(\beta_j = 0\) otherwise. So the BLP is \(\estim{\rX}_{t+h} = \vf_1 \rX_{t+h-1} + \dots + \vf_p \rX_{t+h-p}\). Hence for \(h > p\), we get \[
\pacf(h) = \corr(\rX_t - \estim \rX_t, \rX_{t+h} - \estim \rX_{t+h}) = \corr (\rve_{t+h}, \rX_t - \estim \rX_t) = 0.
\]
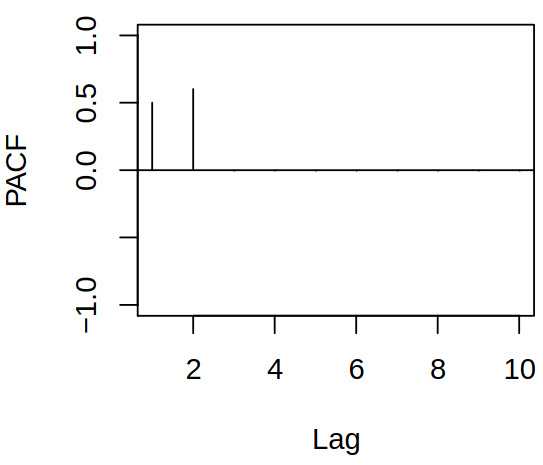
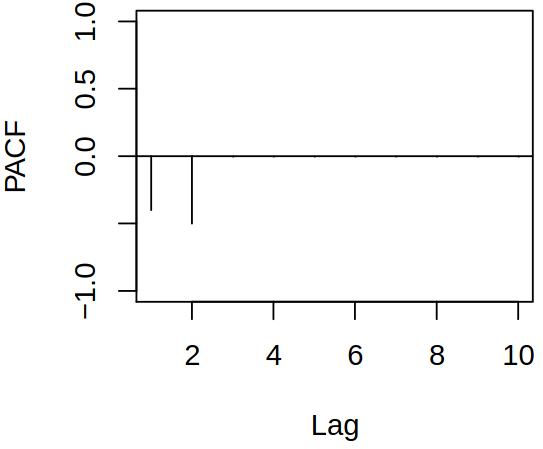
Let \(\rX_t\) be now a causal invertible \(\ARMA{p}{q}\) process \[
\ArPoly{\backs} \rX_t = \maPoly(\backs) \rve_t,
\] then by invertibility, we have the \(\ARmod{\infty}\) representation \[
\rX_t = - \sum_{j = 1}^\infty \pi_j \rX_{t-j} + \rve_t.
\] Thus no finite AR representation exists, hence the PACF does not cut off.
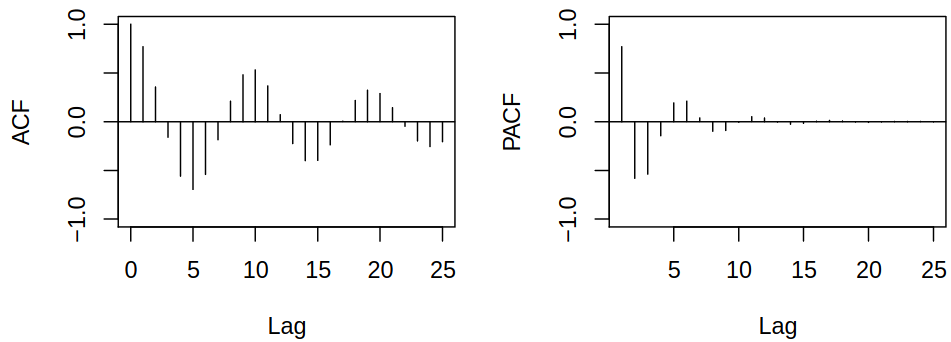
Examples of acf and pacf for ARMA process \(\rX_t = 1.5 \rX_{t-1} - 0.9 \rX_{t-2} + \rve_t - 0.7 \rve_{t-1} + 0.6 \rve_{t-2}\)
We can also check the invertibility and the roots by: