7 ARMA Processes
7.1 From differences equations to ARMA models
Autoregressive models work on the idea that we may want to model or describe real-world phenomena by recurrence relations \[ x_t = g(x_{t-1}, \dots, x_{t-p}), \] for example \(x_t = \vf x_{t-1}\) or \(\Delta x_t \equiv x_t - x_{t-1} = \vf x_{t-1}\). Often it is sufficient to take a linear relation \(g\), thus we get homogeneous linear difference equation of order \(p\) \[ x_t = \vf_1 x_{t-1} + \dots + \vf_p x_{t - p}. \]
We will find these models as a motivation for a class of models for time series or as tools for deriving their properties.
ARMA model stands for AutoRegressive Moving Average model.
7.1.1 Backshift operator
Definition 7.1 (Backshift operator) The backshift (or lag) operator \(\backs\) is the operator that maps a sequence \(\set{x_t; \; t \in \Z}\) to the sequence \(\set{x_{t-1}; \; t \in \Z}\), i.e., element-wise \(\backs x_t = x_{t-1}\).
By a \(k\)-power of \(\backs\) we denote a repeated application \[ \backs^k x_t = \overbrace{\backs \dots \backs}^{k} x_t = x_{t-k}.\] Surely \(\backs^0 x_t = 1x_t = x_t\). We may also notice that this operator is linear \[ a\backs^k x_t + b = a x_{t-k} + b, \] and its difference is defined as \((1 - \backs)x_t = x_t - x_{t-1}\). Considering polynomials, for \(P(z) = \sum_{j = 0}^p \alpha_j z^j\), we get \(P(\backs)x_t = \sum_{j = 0}^p \alpha_j x_{t-j}\). Together, the difference equation \[ x_t - \vf_1 x_{t-1} - \dots - \vf_p x_{t - p} = 0 \] can be written as \[ \ArPoly{\backs}x_t = 0, \] where \(\ArPoly{z} = 1 - \sum_{j = 1}^p \vf_j z^j\).
7.1.2 Solving difference equations
Consider a difference equation \[ x_t - \vf_1 x_{t-1} - \dots - \vf_p x_{t - p} = 0, \] i.e. \(\ArPoly{\backs}x_t = 0\), and let our goal be to find solution(s), i.e. find \(\set{x_t, t \in \N}\) that satisfies this equations. For \(p = 1\), straightforward substitution gives \[ x_t = \vf_1 x_{t-1} = \dots = \vf_1^t x_0. \]
Notice that \(\vf_1\) satisfies \(\ArPoly{\vf_1^{-1}} = 0\). Thus, the solution is of the form \(c \xi_0^{-t}\), where \(\xi_0\) is the root of \(\arPoly\). For \(p > 1\), if \(\xi_0\) is a simple root of \(\arPoly\), we can factorize \(\arPoly\) as \[ \ArPoly{z} = \arPoly^*(z)(1 - \xi_0^{-1}z). \] Hence \(c \xi_0^{-t}\) solves the equation \(\ArPoly{\backs}x_t = \arPoly^*(\backs)(1 - \xi_0^{-1}\backs)x_t = 0\), because it solves the first order equation \((1 - \xi_0^{-1}\backs)x_t = 0\). This procedure can be repeated with all simple roots. On the other hand, if \(\xi_0\) is a root with multiplicity \(m\), then \(\arPoly\) can be factorized as \[ \ArPoly{z} = \arPoly^*(z)(1 - \xi_0^{-1}z)^m, \] where the equation \((1 - \xi_0^{-1}z)^m\) is then solved by \(\xi_0^{-t}, t\xi_0^{-t}, \dots, t^{m-1} \xi_0^{-t}\). Because it can be shown that any non-trivial linear combination of solutions is a solution, then the general solution is given by the following expression \[ \sum_{j = 1}^q \sum_{k = 0}^{m_j-1} c_{jk} t^k \xi_j^{-t}, \] where \(\xi_1, \dots, \xi_q\) are distinct roots with multiplicities \(m_1, \dots, m_q\), i.e. \(\sum_{j = 1}^q m_j = p\). For a pair of complex conjugate roots \(\brackets{\xi_j, \complexConj{\xi_j}}\), the solution becomes \[ \sum_{k = 0}^{m-1} a_{jk}t^k \absval{\xi_j}^{-t} \cos (\complexArg (\xi_j)t + b_{jk}). \]
Note that using initial conditions (values of \(x_t\) at \(p\) time points), we can determine \(c_{jk}\) (and \(a_{jk}, b_{jk}\)).
7.1.3 Stochastic difference equations
In real data, difference equations may not hold exactly as observed data are less regular. But we could theoretically exploit the asymptotic behavior of difference equations: when all roots are outside the unit circle (\(\absval{\xi_j} > 1\)), the solution converges to 0 but in real data, we see stabilization rather than extinction.
To overcome these issues, we may add some randomness to the equation \[ x_t - \vf_1 x_{t-1} - \dots - \vf_p x_{t - p} = 0. \]
Let \(\set{\rve_t, t \in \Z}\) be a sequence of random variables with mean \(0\), variance \(\sigma^2 > 0\) and covariance \(0\) (white noise \(\WN{0}{\sigma^2}\)). Now consider the stochastic difference equation \[ \rnd X_t - \vf_1 \rnd X_{t-1} - \dots - \vf_p \rnd X_{t - p} = \rve_t, \] i.e. \(\ArPoly{\backs}\rnd X_t = \rve_t\). Here \(\rve_t\) are random errors/disturbances/perturbations of the model/random inputs.
Definition 7.2 (Autoregressive (AR) model) The process \(\set{\rX_t, t \in \Z}\) satisfying \[ \rX_t - \vf_1 \rX_{t-1} - \dots - \vf_p \rX_{t - p} = \rve_t, \] where \(\set{\rve_t} \in \WN{0}{\sigma^2}\), is called an autoregressive process of order \(p\).
The Definition 7.2 coins the so-called autoregression \[ \rX_t = \vf_1 \rX_{t-1} + \dots + \vf_p \rX_{t - p} + \rve_t, \] which means that past values are predictors of future values. It is convenient for forecasting and it is constructive, as it describes the underlying physical process and the random data generating process. Moreover, random errors influence future outcomes as they accumulate, i.e. it features the propagation of errors.
Compare, e.g., with linear regression \(\rnd Y_i = \beta_0 + \beta_1 \rnd Z_i + \rnd e_i\) – the outcome is also model (straight line) plus random error, but the errors do not enter as input in the model.
In time series, we have dependent (correlated) sequences of variables. Correlation often becomes small or disappears for observations far apart.
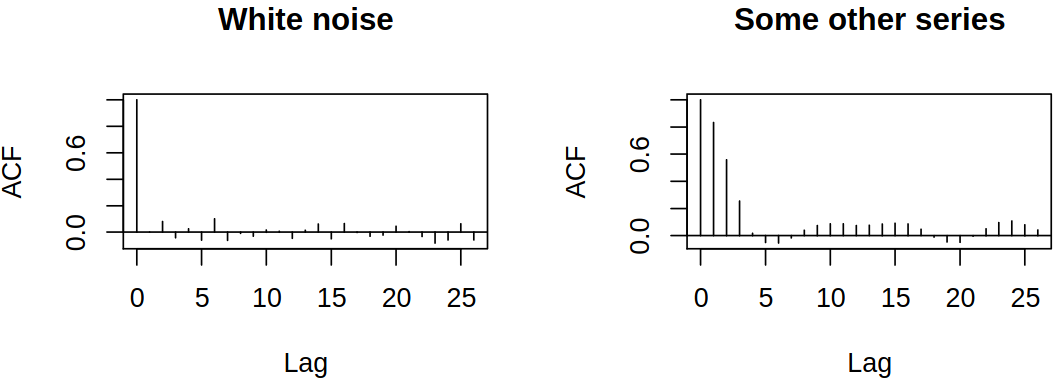
This suggests that we may attempt to construct variables that are correlated up to some lag, then uncorrelated, e.g. consider linear combinations of white noise.
7.1.4 Moving average model
Definition 7.3 The process \(\set{\rX_t, t \in \Z}\) satisfying \[ \rX_t = \rve_t + \tht_1 \rve_{t-1} + \dots + \tht_q \rve_{t-q}, \] for \(t \in \Z\), where \(\set{\rve_t} \sim \WN{0}{\sigma^2}\), is called a moving average process of order \(q\).
Again, we can write \(\rX_t = \maPoly(\backs)\rve_t\) for \(\maPoly(z) = 1 + \tht_1 z + \dots \tht_q z^q\). Obviously, \(\cov \brackets{\rX_t, \rX_{t+h}} = 0\) for \(\absval{h} > q\), and surely it is stationary.
7.2 Towards ARMA models
We have 2 different concepts:
- Deterministic difference equation: the ideal data generating process \[ x_t - \vf_1 x_{t-1} - \dots - \vf_p x_{t - p} = 0; \]
- Stochastic difference equation: ideal process with random perturbation \[ \rX_t - \vf_1 \rX_{t-1} - \dots - \vf_p \rX_{t - p} = \rve_t. \]
Because random inputs (disturbances, errors, …), i.e. uncorrelated variables (white noise) may sometimes be too restrictive, we may want to allow correlated perturbations of the difference equation. Thus we may use an MA process instead of a pure white noise.
Definition 7.4 (ARMA model) The process \(\set{\rX_t, t \in \Z}\) satisfying \[ \rX_t - \vf_1 \rX_{t-1} - \dots - \vf_p \rX_{t - p} = \rve_t + \tht_1 \rve_{t-1} + \dots + \tht_q \rve_{t-q}, \tag{7.1}\] for \(t \in \Z\), where \(\set{\rve_t} \sim \WN{0}{\sigma^2}\), is called an autoregressive moving average process of order \((p,q)\).
Clearly, the equation (7.1) from Definition 7.4 can be re-written as \[ \ArPoly{\backs} \rX_t = \MaPoly{\backs} \rve_t, \quad t \in \Z \] for \[ \arPoly(z) = 1 - \sum_{j = 1}^p \vf_j z^j, \quad \maPoly(z) = 1 + \sum_{k = 1}^q \tht_k z^k. \]
Trivially, \(\ARMA p 0 = \ARmod p\) and \(\ARMA 0 q = \MAmod q\).
7.2.1 Parameter redundancy
Consider now \(\ARMA{0}{0}\) process given by \(\rX_t = \rve_t\). Equivalently, \(\alpha \rX_{t-1} = \alpha \rve_{t-1}\). By subtracting these two equations, we get \[ \rX_t - \alpha \rX_{t-1} = \rve_t - \alpha \rve_{t-1}, \tag{7.2}\] which looks like an \(\ARMA{1}{1}\) process but \(\rX_t\) is still white noise (i.e. \(\rX_t = \rve_t\) solves the equation). Thus we got parameter redundancy (or over-parametrization).
Hence we can rewrite (7.2) in form \(\ArPoly{\backs}\rX_t = \maPoly(\backs)\rve_t\), then \[ (1 - \alpha \backs) \rX_t = (1 - \alpha \backs) \rve_t \] and we can apply \((1 - \alpha \backs)^{-1}\) to get \(\rX_t = \rve_t\). In general, we can do this with all common roots (factors) of \(\arPoly\) and \(\maPoly\) to reduce the complexity of the parametrization.
7.3 Basic properties of ARMA processes
7.3.1 Infinite moving average
Recall the moving average \(\MAmod{q}\) \[ X_t = \ve_t + \tht_1 \ve_{t-1} + \dots + \tht_q \ve_{t-q} \] defined in Definition 7.3. We can extend it to \(\MAmod{\infty}\) as follows \[ \rX_t = \rve_t + \psi_1 \rve_{t-1} + \dots = \sum_{j = 0}^\infty \psi_j \rve_{t-j}. \] Remember now the already presented \(\ARmod{1}\) has the form \[ \rX_t = \vf_1 \rX_{t-1} + \rve_t = \vf_1^2 \rX_{t-2} + \vf_1 \rve_{t-1} + \rve_t = \dots = \vf_1^k \rX_{t-k} + \sum_{j = 0}^{k-1} \vf_1^j \rve_{t-j}, \] then maybe \[ \rX_t = \sum_{j = 0}^\infty \vf_1^j \rve_{t-j}. \] Much care is needed though – the series above should be the limit of random variables \(\sum_{j = 0}^n \psi_j \rve_{t-j}\) as \(n \to \infty\), but we haven’t specified in which sense we view this limit and it is not trivial to determine whether it exists.
7.4 Intermezzo on \(L^2\)
Consider \(L^2(\Omega, \mcal A, P)\) s the set of all random variables on \((\Omega, \mcal A, P)\) with finite second moments (\(\expect X^2 < \infty\)). Then \(L^2(\Omega, \mcal A, P)\) is a linear space. We define \(\scal{\rnd X}{\rnd Y} = \Expect{\rnd X \rnd Y}\), where \(\scal{\rnd X}{\rnd Y}\) is an inner (scalar/dot) product – meaning it is symmetric, linear, \(\scal{\rX}{\rX} \geq 0\) and \(\scal{\rX}{\rX} = 0 \iff \rX = 0\). Also we define the norm \(\norm{\rX} = \scal{\rX}{\rX}^{\frac 1 2} = (\expect \rX^2)^{1/2}\). Two important properties then hold
- \(\norm{\rnd X + \rnd Y} \leq \norm{\rnd X} + \norm{\rnd Y}\) (triangle inequality);
- \(\absval{\scal{\rnd X}{\rnd Y}} \leq \norm{\rnd X} \norm{\rnd Y}\) (Cauchy-Schwarz inequality).
Convergence in this space is the convergence in the norm \(\norm{\cdot}\) \[ \rX_n \inMeanSqWhen{n \to \infty} \rX \iff \norm{\rX - \rX_n}^2 = \Expect{(\rX_n - \rX)^2} \onBottom{\longrightarrow}{n \to \infty} 0, \] which is called convergence in \(L^2\) (or convergence in the mean/convergence in mean-square). Now recall that a sequence is called Cauchy if \(\norm{x_n - x_k} \to 0\) as \(n,k \to \infty\) and that a metric space is called complete if every Cauchy sequence of elements of the space has a limit in the space. Hence it can be deduced that \(L^2\) is a Hilbert space.
A space with inner product, that is complete, i.e. every Cauchy sequence has the limit in the space, is called Hilbert space.
7.5 Existence of linear processes
Theorem 7.1 If \(\set{\rve_t, t \in \Z} \sim \WN{0}{\sigma^2}\) and the sequence \(\set{\psi_j, j \in \Z}\) is such that \(\sum_{j = 1}^\infty \psi_j^2 < \infty\), then the random series \(\sum_{j = 0}^\infty \psi_j \rve_{t - j}\) converges in \(L^2\), i.e., there is a variable \(\rnd Y \in L^2(\Omega, \mcal A, P)\) such that \[ \Expect{\rnd Y - \sum_{j = 0}^n \psi_j \rve_{t - j}} \to 0 \] as \(n \to \infty\).
Proof. Since \(L^2\) is a Hilbert space, it is enough to verify the Cauchy criterion, which is implied by the following: \[ \Expect{\sum_{j = 0}^{n+m} \psi_j \rve_{t - j} - \sum_{j = 0}^{n} \psi_j \rve_{t - j}}^2 = \sum_{j,k = n+1}^{n+m} \psi_j \psi_k \Expect{\rve_j \rve_k} = \sum_{j = n+1}^{n+m} \psi_j^2 \sigma^2 \to 0. \]
Similarly, we can formulate a more general theorem.
Theorem 7.2 If \(\set{\rnd Y_t, t \in \Z}\) is a mean zero stationary sequence and the sequence \(\set{\psi_j, j \in \Z}\) is such that \(\sum_{j = 1}^\infty \absval{\psi_j} < \infty\), then the random series \(\sum_{j = 0}^\infty \psi_j \rnd Y_{t - j}\) converges in \(L^2\) (in mean square) and also absolutely with probability \(1\).
This way we assumed all general stationary processes (not only white noise) and got almost sure convergence (not only in \(L^2\)). Thus given a linear process \[ \rX_t = \sum_{j = 0}^\infty \psi_j \rve_{t - j} \] with mean \[ \expect {\rX}_t = \sum_{j = 0}^\infty \psi_j \expect \rve_{t - j} = 0 \] and covariance \[ \begin{aligned} \cov (\rX_s, \rX_t) &= \Expect{\brackets{\sum_{j = 0}^\infty \psi_j \rve_{t - j}} \brackets{\sum_{j = 0}^\infty \psi_j \rve_{t - j}}} \\ &= \sum_{j,k = 1}^\infty \psi_j \psi_k \Expect{\rve_{s-j} \rve_{t-k}} = \sum_{j = 0}^\infty \psi_j \psi_{j + \absval{t-s}} \sigma^2, \end{aligned} \] it follows that \(\set{\rX_t}\) is weakly stationary, see Definition 3.2.
7.6 Causality
Consider \(\ARmod{1}\) and iteratively substitute \[ \rX_t = \vf_1 \rX_{t-1} + \rve_t = \vf_1^2 \rX_{t-2} + \vf_1 \rve_{t-1} + \rve_t = \dots = \vf_1^k \rX_{t-k} + \sum_{j = 0}^{k - 1} \vf_1^j \rve_{t-j}, \] then if \(\absval{\vf_1} < 1\) and \(\set{\rX_t}\) is stationary, the the remainder term \(\vf_1^k \rX_{t-k}\) goes to 0 in \(L^2\) as \(k \to \infty\), because \[ \Expect{(\vf_1^k \rX_{t-k})^2} = \vf_1^{2k} \Expect{\rX_{t-k}^2} \to 0. \]
Also the series \(\sum_{j = 0}^\infty \vf_1^j \rve_{t-j}\) converges because \(\sum_{j = 0}^\infty (\vf_1^j)^2 < \infty\). Hence we have the causal representation \[ \rX_t = \sum_{j = 0}^\infty \vf_1^j \rve_{t - j}, \] where causal means the current state depends on some history. We can also iterate in the opposite direction \[ \begin{aligned} \rX_t &= \vf_1^{-1} \rX_{t+1} - \vf_1^{-1} \rve_{t+1} \\ &= \vf_1^{-2} \rX_{t+2} - \vf_1^{-2} \rve_{t+2} - \vf_1^{-1} \rve_{t+1} \\ &= \dots \\ &= \vf_1^{-k} \rX_{t+k} - \sum_{j = 1}^{k - 1} \vf_1^{-j} \rve_{t+j}, \end{aligned} \] so if \(\absval{\vf_1} >1\) and \(\set{\rX_t}\) is stationary, we get the future dependent representation \[ \rX_t = - \sum_{j = 1}^\infty \vf_1^{-j} \rve_{t+j}. \]
Hence a stationary solution exists, but is practically useless, because it requires the knowledge of the future for the prediction of the future. Also note that for \(\absval{\vf_1} = 1\), the process is not stationary (we get a random walk).
Definition 7.5 (Causality) An \(\ARMA{p}{q}\) process is said to be causal if there exists a sequence \(\set{\psi_j, j \in \N_0}\) such that \(\sum_{j = 0}^\infty \absval{\psi_j} < \infty\) and \[ \rX_t = \sum_{j = 0}^\infty \psi_j \rve_{t - j}, \quad t \in \Z, \] where \(\vi \psi\) is called a filter and this representation is called a causal representation of the process.
Since \[ \sum_{j = 0}^\infty \psi_j^2 \leq \brackets{\sum_{j = 0}^\infty \absval{\psi_j}}^2 < \infty, \] a causal process is a linear process. Also since linear processes are stationary, causal ARMA processes are stationary.
7.6.1 Causality of an autoregressive process of order \(p\)
Consider an \(\ARmod{p}\) process of the form \(\arPoly(\backs) \rX_t = \rve_t\). Let us try to find its causal representation. First, we factorize \[ \arPoly(z) = \prod_{j = 1}^r \brackets{1 - \xi_j^{-1} z}^{m_j}, \] where \(\xi_j\) are the distinct roots with multiplicities \(m_j\), \(\sum_{j = 1}^r m_j = p\). Thus \[ \brackets{1 - \xi_1^{-1}}^{m_1} \cdot \dots \cdot \brackets{1 - \xi_r^{-1}}^{m_r} \rX_t = \ve_t. \] So if \(\absval{\xi_j^{-1}} < 1\) (i.e. \(\absval{\xi_j} >1\)), we have \(\brackets{1 - \xi_j^{-1}}^{-1} = \sum_{h = 0}^\infty \xi_j^{-h} \backs^h\). Then we successively apply \(\brackets{1 - \xi_1^{-1}}^{-1}\) to both sides to work out the coefficients. The key assumption here is that all roots of \(\arPoly(z)\) lie outside the unit circle.
Theorem 7.3 Let \(\set{\rX_t}\) be an \(\ARMA{p}{q}\) process for which the polynomials \(\arPoly\) and \(\maPoly\) have no common roots (otherwise we can cancel them out). Then \(\set{\rX_t}\) is causal if and only if all roots of \(\arPoly\) lie outside the unit circle, i.e., \(\arPoly(z) \neq 0\) for all \(z \in \C\) such that \(\absval{z} \leq 1\). Then coefficients \(\set{\psi_j}\) can be determined by the relation \[ \Psi (z) = \sum_{j = 0}^\infty \psi_j z^j = \maPoly(z) / \arPoly(z), \quad \absval{z} \leq 1. \]
7.6.2 Non-uniqueness of MA models and inverting them
Consider two \(\MAmod{1}\) models \[ \begin{gathered} \rX_t = (1 + \tht_1 \backs) \rve_t, \quad \rve_t \sim \WN{0}{\sigma^2}, \\ \rX_t^* = (1 + \tht_1^{-1} \backs) \rve_t^*, \quad \rve_t^* \sim \WN{0}{\tht_1^2 \sigma^2}, \end{gathered} \] then both \(\rX_t\) and \(\rX_t^*\) have the same autocovariance fuction \[ \acov(0) = (1 + \tht_1^2)\sigma^2, \quad \acov (1) = \tht_1 \sigma^2, \quad \acov (h) = 0 \] for \(\absval{h} >1\). Hence we have two representations for the same covariance structure of the observed process (if \(\tht_1 \neq 1\)). Thus we choose one of them – by mimicking the idea of causality for AR, we choose the invertible one, that is, \(\rX_t\) if \(\absval{\tht_1} < 1\) and \(\rX_t^*\) if \(\absval{\tht_1} > 1\).
Therefore, WLOG, let us assume that \(\absval{\tht_1} < 1\). Then we can invert \(\MAmod{1}\) to get the its \(\ARmod{\infty}\) representation \[ \rve_t = \brackets{1 + \tht_1 \backs}^{-1} \rX_t = \sum_{j = 0}^k (-\tht_1)^j \rX_{t-j}. \]
Consider now a moving average process \(\MAmod{q}\) \[ \rX_t = \maPoly(\backs)\rve_t, \quad t \in \Z. \] Then we factorize \(\maPoly\) to get \[ \rX_t = \brackets{1 - \xi_1^{-1}\backs}^{m_1} \cdot \ldots \cdot \brackets{1 - \xi_r^{-1}\backs}^{m_r} \rve_t, \] where \(\xi_j\) are the distinct roots with multiplicities \(m_j\), \(\sum_{j = 1}^r m_j = p\). Thus, WLOG, we assume that \(\absval{\xi_j^{-1}} < 1\), that is, all roots of \(\maPoly(z)\) are outside the unit circle (possibly after flipping to the reciprocal in each factor and multiplying the error variance as shown before).
Analogously to the \(\ARmod{p}\) case, we can invert the \(\MAmod q\) representation and successively apply \(\brackets{1 - \xi_j^{-1}\backs}^{-m_j}\) to both sides to get the infinite AR representation (or invertible representation) \[ \rve_t = \sum_{j = 0}^\infty \pi_j \rX_{t-j}. \]
Notice that \(\rX_t = \sum_{j = 1}^\infty \rX_{t-j} + \rve_t\), which is \(\ARmod{\infty}\) process.
Definition 7.6 An \(\ARMA{p}{q}\) process is said to be invertible if there exists a sequence \(\set{\pi_j, j \in \N_0}\) such that \(\sum_{j = 0}^\infty \absval{\pi_j} < \infty\) and \[ \rve_t = \sum_{j = 0}^\infty \pi_j \rX_{t - j}, \quad t \in \Z. \]
Theorem 7.4 Let \(\set{\rX_t}\) be an \(\ARMA{p}{q}\) process for which the polynomials \(\arPoly\) and \(\maPoly\) have no common roots. Then \(\set{\rX_t}\) is invertible if and only if all roots of \(\maPoly\) lie outside of the unit circle, i.e., \(\maPoly(z) \neq 0\) for all \(z \in \C\) such that \(\absval{z} \leq 1\). The coefficients \(\set{\pi_j}\) can be determined by relation \[ \Pi(z) = \sum_{j = 0}^\infty \pi_j z^j = \arPoly(z) / \maPoly(z), \quad \absval{z} \leq 1. \]